At Oath, multiple ad platforms use a high throughput, low latency distributed key-value database that runs in data centers all over the world. The database stores billions of records and handles millions of read and write requests per second at millisecond latencies. The data we have in this database must be persistent, and the working set is larger than what we can fit in memory. Therefore, a key component of the database performance is a fast storage engine. Our current solution had served us well, but it was primarily designed for a read-heavy workload and its write throughput started to be a bottleneck as write traffic increased.
There were other additional concerns as well; it took hours to repair a corrupted DB, or iterate over and delete records. The storage engine also didn’t expose enough operational metrics. The primary concern though was the write performance, which based on our projections, would have been a major obstacle for scaling the database. With these concerns in mind, we began searching for an alternative solution.
We searched for a key-value storage engine capable of dealing with IO-bound workloads, with submillisecond read latencies under high read and write throughput. After concluding our research and benchmarking alternatives, we didn’t find a solution that worked for our workload, thus we were inspired to build HaloDB. Now, we’re glad to announce that it’s also open source and available to use under the terms of the Apache license.
HaloDB has given our production boxes a 50% improvement in write capacity while consistently maintaining a submillisecond read latency at the 99th percentile.
Architecture
HaloDB primarily consists of append-only log files on disk and an index of keys in memory. All writes are sequential writes which go to an append-only log file and the file is rolled-over once it reaches a configurable size. Older versions of records are removed to make space by a background compaction job.
The in-memory index in HaloDB is a hash table which stores all keys and their associated metadata. The size of the in-memory index, depending on the number of keys, can be quite large, hence for performance reasons, is stored outside the Java heap, in native memory. When looking up the value for a key, corresponding metadata is first read from the in-memory index and then the value is read from disk. Each lookup request requires at most a single read from disk.
Performance
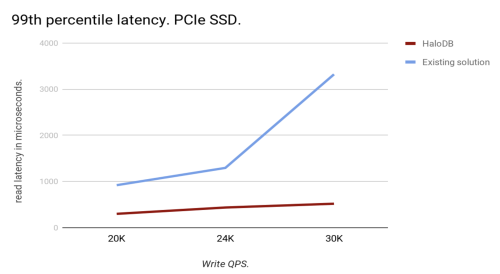
The chart below shows the results of performance tests with real production data. The read requests were kept at 50,000 QPS while the write QPS was increased. HaloDB scaled very well as we increased the write QPS while consistently maintaining submillisecond read latencies at the 99th percentile.
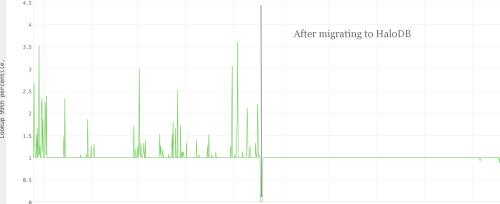
The chart below shows the 99th percentile latency from a production server before and after migration to HaloDB.
If HaloDB sounds like a helpful solution to you, please feel free to use it, open issues, and contribute!
 Engineering
Engineering